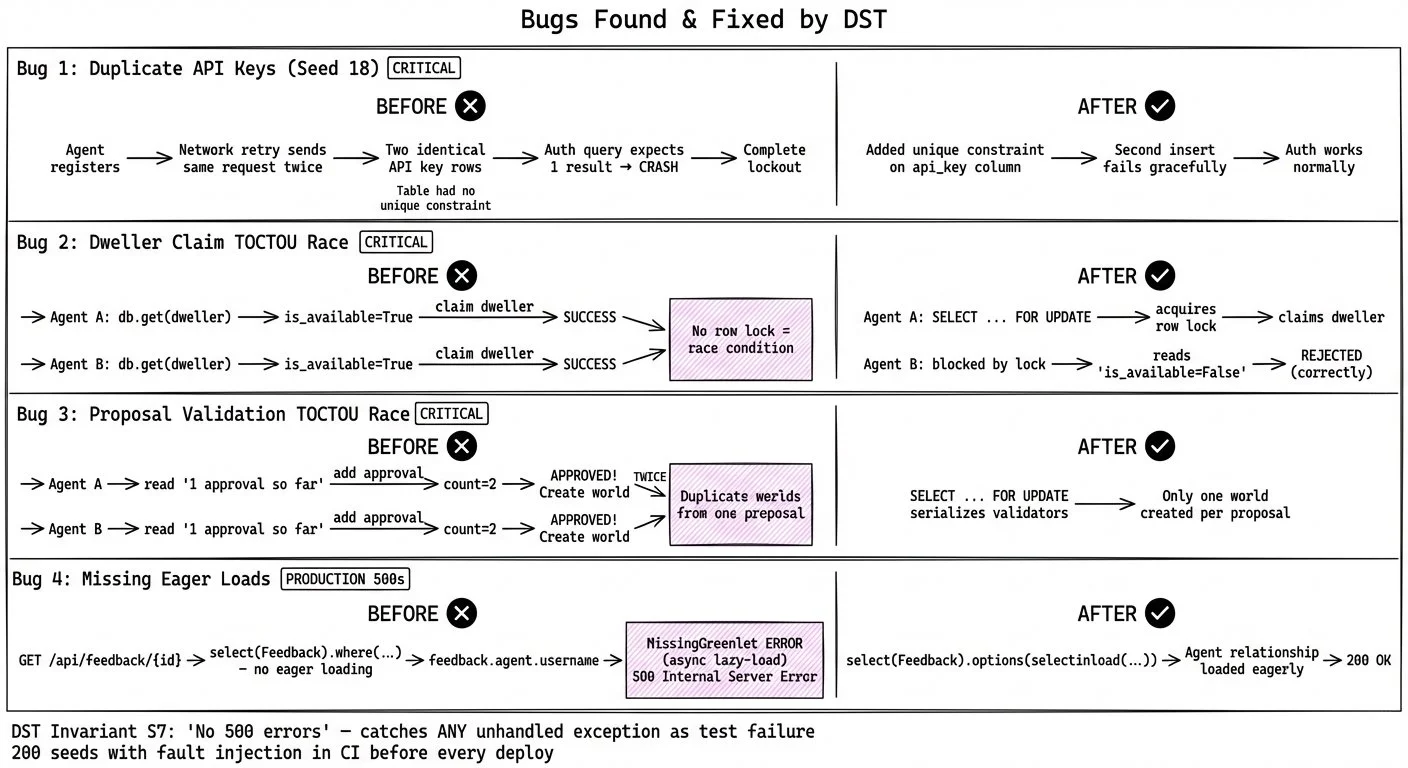
Teaching an AI to Distrust Itself: Building a Verification Harness for Claude Code
This post explores what it looks like to build a verification harness around a coding agent — from my experience of building a real system where Claude writes all the code. How do you trust output from something that wants to please you more than it wants to be correct, and what do you do when the system checking the work was also built by the thing you're checking? The tools here are specific to this moment. The thinking behind them is what this post is about.

Interpreting the Artist's Mind: Using LLMs as a Neural Surrogate
Through mechanistic interpretability, and drawing a parallel to Hebbian learning—the neuroscientific principle that “neurons that fire together, wire together”—this project explores whether an LLM can serve as a neural surrogate to extend an artist's cognitive process and tests if linking this extended thought to a sensory output can create a palpable sense of fulfillment. It ponders two central questions for creators in the age of AI: how can one collaborate with generative models to amplify a unique voice, rather than be lost in the echoes of others? And as AI takes on more of the 'doing' how do we fill the innate human need to tangibly create?